工程师视角:机器学习赋能专利检索
作为一名长期从事专利领域的NLP工程师,曾也是某最权威专利检索系统(上一代和现行系统)的核心架构师、算法工程师,我只想说: 脱离不了以下知识点 ~~~~
当然规划的下一代:大模型 + 智能体……
以下是废话(文不都是这么开头么):
全球专利数据的数量正以惊人的速度增长,形成一片浩瀚的信息海洋。对于研发人员、知识产权专家和企业战略家而言,在这片海洋中精准、高效地航行,找到关键技术信息,是一项至关重要的挑战。传统的检索方法,如简单的关键词匹配,常常因无法理解复杂的语言和技术概念而显得力不从心,导致检索结果要么遗漏关键信息,要么被大量无关文档淹没。
下面才是重点,脱离不了的重点: 深入解析三种主流的AI检索技术: 词法检索(Lexical Search) 、 语义检索(Semantic Search) 和 混合检索(Hybrid Search) 。本文的目标是帮助您理解权威检索系统的技术原理及其优缺点。
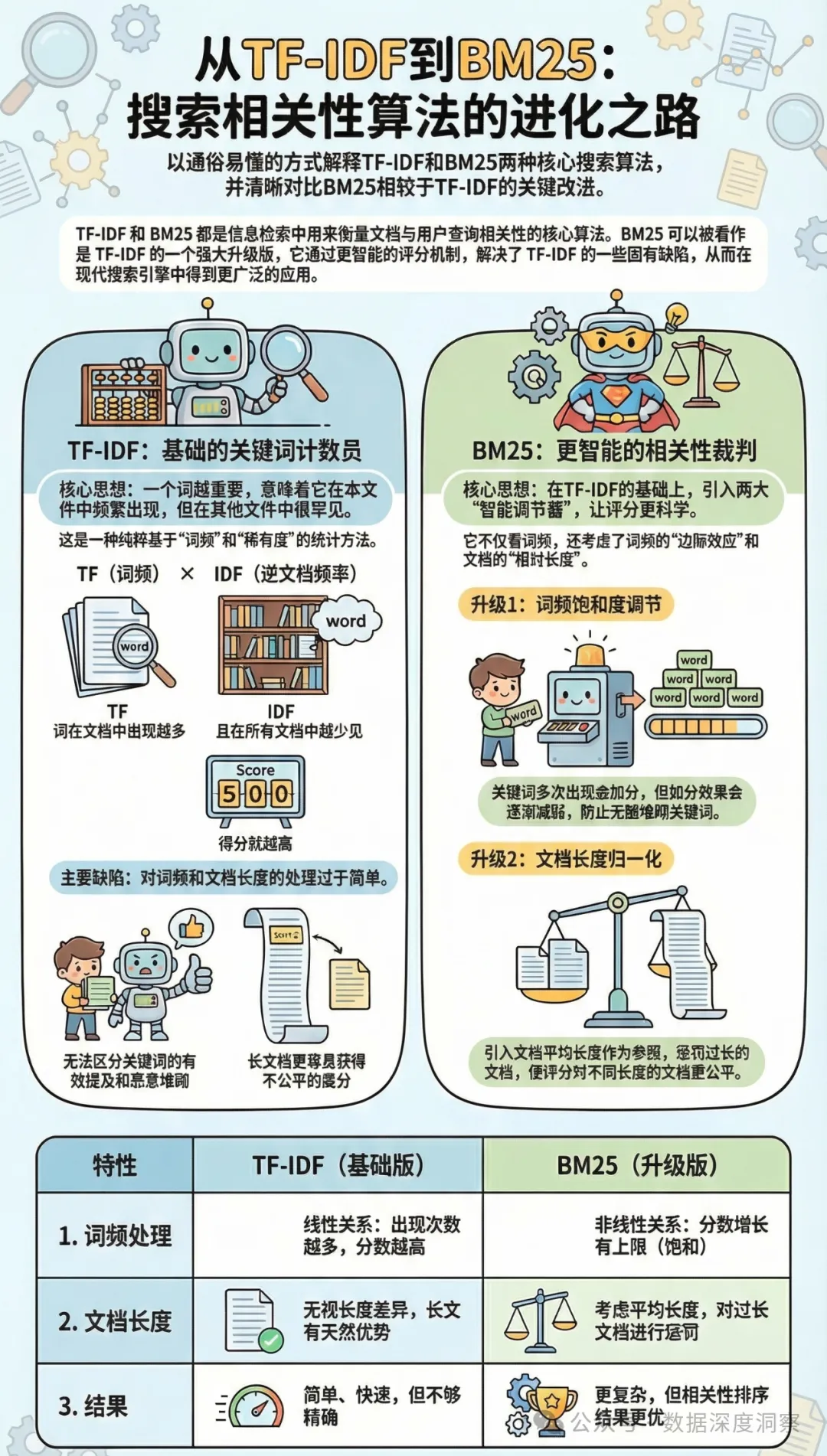
1、 基础方法:词法检索 (Lexical Search)
词法检索,通常也称为关键词检索,是信息检索领域最基础也是最成熟的方法。它不理解文字的“意义”,而是通过统计学方法来识别和排序文档。
其核心技术是 TF-IDF (Term Frequency-Inverse Document Frequency) 和在此基础上发展的 Okapi BM25。我们可以将其简单理解为一种“计算词语并赋予重要性分数”的机制。一个词在某篇专利中出现得越频繁(TF),同时在整个专利数据库中越稀有(IDF),那么这个词对于这篇专利就越重要,得分也越高。BM25则是在TF-IDF的基础上进行了优化,考虑了文档长度等因素,使评分更加合理。
核心优势
- 简单快速:算法原理直观,计算速度快,能迅速处理大规模数据集。
- 无需训练:它是一种纯粹的统计方法,不需要预先训练复杂的机器学习模型。
- 精准匹配:对于包含特定关键词、化学式、产品型号或专有名称的查询,词法检索的效果极佳。
- 计算开销低:由于其统计学基础,TF-IDF和BM25在性能和成本之间取得了很好的平衡,在许多场景下是极为明智的选择。
主要局限
- 它无法理解词语的语义或上下文。对于同义词(如“电池”和“蓄电装置”)或相关概念,它会将其视为完全不相关的词,从而导致信息遗漏。
2、 技术演进:语义检索 (Semantic Search) — 理解语境的“智能顾问”
随着自然语言处理(NLP)技术的发展,语义检索应运而生。它不再仅仅是匹配字符串,而是真正尝试去“理解”查询和文档背后的概念和意图,堪称一次技术上的演进。
其核心技术是词嵌入(Word Embedding)模型,如 Word2vec、GloVe 和更现代的 BERT。这些模型通过深度神经网络在海量文本数据上进行训练,学习将每个词语表示为一个低维度的密集向量(dense vector)。其基本思想是:“在相似上下文中出现的词语,其向量表示也应该相似。”
核心优势
- 捕捉语义:能够理解同义词、近义词和相关概念。
- 理解上下文:同一个词在不同语境下可以有不同的含义,语义模型能够捕捉这种细微差别。
- 发现关联:能找到那些虽然用词完全不同,但描述的是同一个技术概念的专利。
主要局限
- 训练成本高昂:需要大量的训练数据和较长的训练时间,并且对计算设施要求严苛。例如,BERT这样的大型模型需要高性能服务器,其训练过程会消耗巨大的计算资源,并产生可观的碳排放。
- 结果难以溯源:模型的“可解释性”相对较差。当需要向专利律师或审查员解释为何某篇文献被检索出来时,无法像词法检索那样直接指出匹配的关键词,这在严谨的法律场景中可能成为沟通障碍。
当检索的目标是一个抽象的技术概念,或者发明使用了新颖的、尚未普及的术语时,语义检索就变得不可或缺。
场景示例
一项新发明描述了一种“利用嵌入离子的柔性储能单元”,在专利申请中从未出现过“锂离子电池”这个词。如果只用词法检索,很可能会错过所有关于锂离子电池的现有技术。然而,语义检索能够理解“柔性储能单元”和“嵌入离子”在技术概念上与“电池”、“蓄电”等高度相关。就像它能理解“我爱狗”和“我喜欢小狗”表达了相似的情感一样,它也能跨越术语的障碍,找到那些描述了相同技术核心但使用了不同措辞的关键专利文献。

3、 前沿融合:混合检索 (Hybrid Search) — 两全其美的“终极方案”
既然词法检索和语义检索各有千秋,那么能否将二者结合,取长补短?答案是肯定的,这就是混合检索。
混合检索是一种将稀疏向量(由BM25等词法算法生成)和密集向量(由语义模型生成)相结合的先进技术。它旨在同时利用词法检索的关键词匹配能力和语义检索的上下文理解能力,从而提供最全面、最相关的检索结果。
工作原理
混合检索系统会并行执行词法检索和语义检索。例如,对于查询“如何捕捞阿拉斯加鳕鱼”,词法检索(稀疏向量)会精准匹配“Alaskan Pollock”这个关键词,而语义检索(密集向量)则能理解“捕捞”的含义是“fishing”,而不是“捕捉疾病”或“打棒球”。
随后,系统会使用一种融合算法,如 倒数排名融合(Reciprocal Rank Fusion, RRF),将两组检索结果合并成一个统一的、相关性更高的排序列表。RRF算法通过惩罚在任一列表中排名较低的文档,确保了来自两种检索方法的高相关性结果都能被优先呈现。例如,假设文档A在关键词检索中排名第1,在语义检索中排名第3;而文档B在关键词检索中排名第2,在语义检索中排名第1。RRF会赋予文档B更高的最终得分,因为它在两个列表中都获得了较高的排名,展现了更均衡的相关性。这种机制确保了不会过度偏向某一种检索方法的结果。
在专利无效性分析或自由实施(Freedom-to-Operate, FTO)检索等高风险场景中,任何信息的遗漏都可能导致巨大的商业损失。这类任务对检索的要求极为苛刻。
场景示例
一家公司准备上市一款新产品,需要进行全面的FTO分析。这项工作既需要极高的精确率(必须找到所有提及竞争对手特定产品名称或专利号的文献),也需要极高的召回率(必须发现所有在技术概念上相似,可能构成侵权风险的现有技术,无论其措辞如何)。
在这种情况下,混合检索是理想的解决方案。它能确保不会错过任何包含关键术语的文档(词法检索的功劳),同时也能最大限度地挖掘出所有概念相关的潜在风险文献(语义检索的功劳),从而为决策提供最全面的信息支持。

在专利分析领域,不存在放之四海而皆准的“最佳”检索技术。最优的选择完全取决于当前任务的具体需求。在我们的实践中,标准的专利分析流程通常始于一次全面的BM25检索,以建立精确匹配的基线;随后,我们应用语义或混合检索层,来发掘那些使用了不同术语但概念上高度相关的潜在现有技术,从而确保分析的深度与广度。对于简单、明确的关键词验证任务,高效的词法检索依然是首选;而当面对复杂的概念探索和高风险的尽职调查时,则需要充分利用语义检索和混合检索的强大能力。
随着AI技术的不断演进,从词法到语义再到两者的融合,我们驾驭海量专利信息的能力正在发生质的飞跃。理解并善用这些工具,将成为每一位知识产权从业者在未来竞争中脱颖而出的关键。这些技术的持续发展,正深刻地改变着知识产权分析的面貌,并为技术创新和商业决策提供前所未有的洞察力。